Advanced SEO with TF-IDF: What is TF-IDF, how will it help content optimization
How do search engines do what they do?
To first understand TF-IDF, let's look at how search engines fundamentally work.
Search engines have crawled and indexed all of the sites that make up the internet. When faced with a user query, how do they figure out which pages are most relevant?
The internet is a vast library with many websites and pages. How do search engines find this information?
They do this by using Information Retrieval principles, which is to find the most closely related document(site/web page) in the corpus(collection/internet).
When they crawl a site, they construct a model of the site content in n-dimensional space that represents what the site is all about. They do the same for the user’s search and construct a query model as points connected in this n-dimensional space.
How does a search engine determine content relevance? By looking at the site whose content model is in closest proximity to the user's query model. The closer the page is to the query in this n-dimensional space, the more relevant it is.
To be sure any mature search engine uses many factors such as authority, backlinks among many others to figure out rankings, but at a fundamental level, content is the real basis of determining relevance.
The closer your site's content model is to others that are close to the user's query, the better your chances of getting to the higher ranking.
One well known and most commonly used algorithm in Information Retrieval is TF-IDF. This algorithm forms the basis of most search engines.
What is TF-IDF?
At a simplistic level, it involves converting every site into a model represented by terms(words, a single word, phrases, etc) with a score attached to each term.
There are three parts to score calculation -
- 1. Term Frequency
- 2. Inverse Document Frequency
- 3. Normalization
TF - Term Frequency
Term Frequency at a basic level is a count of how many times a term appears in any given document.
The essential thing to keep in mind here is that relevance does not increase proportionately with term frequency. A document with 10 occurrences of the term may be more relevant than one with just 1 occurrence, but it is not 10 times as relevant. Therefore it is rarely useful in its base form. That would just be a simple keyword count.
There are many ways to calculate term frequency -
Natural TF
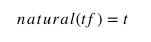
Where t is the number of times a term occurs in the document
Adjusted TF
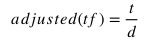
Where d is the number of terms in the document.
Logarithmic TF
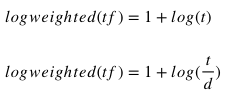
Augmented TF
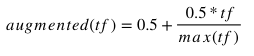
Where max(tf) is the most occuring term in the document
Log Average TF
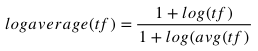
If you are not familiar with the log function in math, its use is to essentially dampen the effect of a raw count. As an example log(1) = 1, log(10) = 2 and so on.
DF - Document Frequency
Document Frequency is a count of how many times that term appears in the set of documents - in the entire corpus and for our purpose in the entire internet
It is usually calculated as
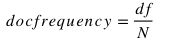
Where df is the number of documents that contain the term and N is the total number of documents in the corpus or collection.
In Information Retrieval, the idea is that a term that occurs too often in the entire collection is not as important as one that occurs less frequently. And therefore, the inverse of the document frequency is more important.
IDF - Inverse Document Frequency
Again for this there are many flavors you can use
Log IDF
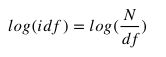
Smooth IDF
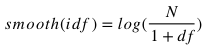
Probabilistic IDF
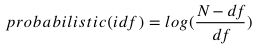
So in simplest terms
TF-IDF = TF multiplied by IDF
Normalization
These are operations done to the scores to cancel out effects of document length. Long and short documents which are both in proximity to the user content model can then have similar weights.
Commonly used ones are cosine equivalent, pivoted unique and byte size. The math behind these is fairly complex, and therefore we won’t go into explaining that here.
Every search engine out there uses one flavor each for the three parts above - one method to calculate TF, another for IDF and a third one for normalization.
Seems straight forward enough, so where is the catch?
Using one of each of the three components- term frequency, inverse document frequency and normalization, you could calculate the scores and be on your way, so where is the catch?
Well to get accurate calculations for IDF, your corpus needs to be the entire internet. You would have to crawl all the sites and store all their models internally and then serve up the scores.
Since most of us aren't in the business of being search engines, how do we get around this?
What you can do instead is reverse-engineer what a search engine does and use the sites it thinks are important. Again, there are many ranking factors, but at the end of the day, content is the essential factor.
It stands to reason that sites in the top of the ranking should have content that is already relevant to the search query.
What we do is find these terms and calculate their scores using a formula based on the three components above and then compare them to your site's content and scores.
How does this help me?
Based on the scores we make a recommendation; give you data that you can use immediately to improve your rankings.
Use our algorithm to uncover terms you may have missed entirely, terms that you haven't used as often as well as terms that you may have overused which could lead to an overuse penalty.
TF IDF is a simplistic algorithm theorized in the 70s, and technology has come a long, long way since. However, it is a fundamental Information Retrieval theory on which other algorithms are built.
The algorithm we use is a TF-IDF variation at heart, but we have used other information retrieval principles, added a proprietary method of weighting and refined it to be a better reverse engineering substitute than basic Term Frequency/Weighted Document Frequency algorithms.
Check if your content is holding you back